作者 | Aimme
出品 | 焉知
一直想通过计算机视觉的角度好好地把其在自动驾驶视觉检测、追踪及融合上的原理进行详细阐述,对于下一代自动驾驶系统来说,会采用集中式方案进行摄像头的原始感知信息输入和原始雷达目标的输入。对于纯摄像头的感知方案通常采用针孔相机模型进行相机标定,在本文中,将研究相机配准和雷达传感器融合的整体过程。了解其对于掌握后续关于测量提取和传感器校准的讨论是必要的。
单/双目相机标定基本原理
将相机信息与物理世界相关联,需要描述 3D 世界坐标和图像坐标之间数学关系的模型,计算机视觉中最简单的此类模型是针孔相机模型(如下图)。
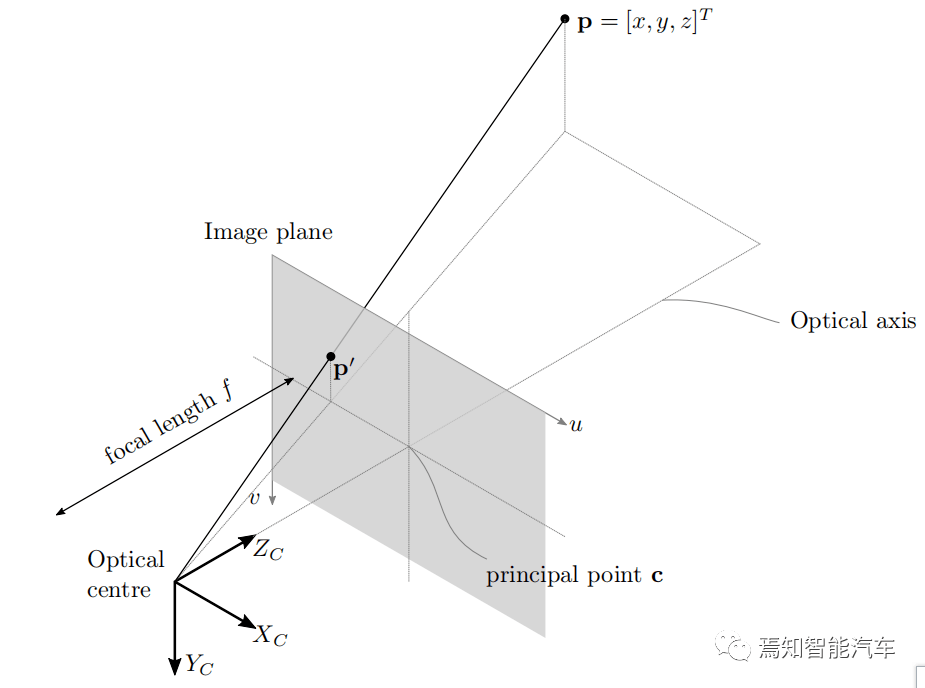
图1 相机模型模型的投影
针孔模型中的图像形成是通过假设一个无限小的孔径来解释的,因此用了针孔这个术语。考虑上图中所有光线会聚在光学中心上,该中心与相机参考系的原点重合,光心到像面上主点c的距离等于焦距f,来自点 p = [x,y,z] T的光线穿过光学中心,从而投影到位于图像平面上的点 p’= [x’,y’,z’] T。相似三角形的原理规定,点 [x,y,z] T 被映射到图像平面上的点 p’= [fx/z, fy/z, f] T 。忽略深度,该投影由 R3(三维)到 R2(二维)映射给出,即
(1)
引入齐次坐标,如上图像点信息可以改写为矩阵形式,其中K表示相机校准矩阵。
免责声明:本文仅代表文章作者的个人观点,与本站无关。其原创性、真实性以及文中陈述文字和内容未经本站证实,对本文以及其中全部或者部分内容文字的真实性、完整性和原创性本站不作任何保证或承诺,请读者仅作参考,并自行核实相关内容。
举报邮箱:3220065589@qq.com,如涉及版权问题,请联系。
















网友评论